
티스토리 뷰
Diffusion model를 이해하는데, 통계확률적 기반이 많이 사용되어, 이참에 좀더 구조가 간단하고 확률적 생성모델인 VAE를 공부해보려고 하는데, Distribution ("분포")에 대한 백그라운드가 적어서 그런지 시간이 걸린다.
여튼, VAE는 AutoEncoder와 거의 유사한 구조의 모델이지만, Latent를 만들어내는 방식이 다르다. AutoEncoder에서는 Compressed된 형태의 Latent vector를 생성하여 얼마나 입력과 얼마나 유사한 출력을 갖는지에 관심이 있는 반면, VAE에서는 생성 모델이다 보니, 유사하지만 새로운 형태의 출력을 어떻게 만들것인가가 관건이다. 이를 위해서 Loss 함수는 두개의 Loss term들을 갖는다.
첫번째, AE와 같이 "Reconstruction Error"로 loss 함수로 갖지만, 확률적 생성모델로서 역활을 할 수 있도록 Encoder는 확률적 Latent Vector를 만들어야 하고, 이러한 Latent Vector의 확률적 접근을 위해 KL Divergence를 활용한다. KL Divergence loss 함수를 이용하여 Encoder가 만들어내는 Latent Vector인 "z"가 가능한 평균이 0이고 분산이 1인 정규분포를 따르도록 강제한다. z는 다차원 벡터일 수 있고 각 차원이 생성에 있어 임의의 특징을 나타낸다고 볼수 있기 때문에 z를 구성하는 각 차원 값은 정규분포에서 sampling한 값으로 사용하게 된다.
KL Divergence
There are two loss functions in training a Variational AutoEncoder: 1. Mean Square Error (MSE) loss to compute the loss between the input image and the reconstructed image, and 2. KL divergence to compute the encoded distribution and the normal distribution with 0 mean and 1.0 variance.
- https://medium.com/@outerrencedl/variational-autoencoder-and-a-bit-kl-divergence-with-pytorch-ce04fd55d0d7
여튼 초기에 Encoder가 만들어내는 분포와 N(0,1)의 KLD가 맞는 건가?하는 고민이 있었는데,
계속 고민하다가 Jeremy Jordan의 글을 읽게 되었는데, 꽤나 도움이 되었다.
https://www.jeremyjordan.me/variational-autoencoders/
Variational autoencoders.
A variational autoencoder (VAE) provides a probabilistic manner for describing an observation in latent space. Thus, rather than building an encoder which outputs a single value to describe each latent state attribute, we'll formulate our encoder to descri
www.jeremyjordan.me
Jeremy의 글에서 느낀 것은 "하나의 Latent Representation"을 찾아내는 것이 아니라, "확률변수로써의 Latent"를 찾아내는 것!
예를 들어, Encoder-Decoder에서 Latency Vector가 3차원의 값 [3, 4, 5]라고 가정하면, VAE에서는 Latent Vector가 [N(3, sigma1), N(4, sigma2), N(5, sigma3)] 라고 해야할까?!!!
VAE에서는 이를 위해서 mu vector와 log_variance vector를 Encoder가 만들어내고, mu vector와 log_variance vector를 이용하여 확률적 Latent vector를 구성한 후, 이를 Decoder에 전달하게 된다.
여기서, mu와 variance를 N(0,1)로 가져가려고 하는 것 (KL Divergence를 통해)은 일종의 Regularizer와 같은 기능을 한다고 한다. 이는 Reconstruction Loss 함수가 전통적인 AutoEncoder에서 처럼 특정 latent값을 만들려고 노력하는 경향이 있는데, 이러한 특정 값의 Latent를 만드는 것은 생성 모델 측면에서 문제가 있기 때문에, KL Divergence를 통하여 생성 모델로써 적합한 확률적 Lantent를 만들수 있도록 Reconstruction Loss의 Regularizer로써의 역활을 하게 되는 것 같다.
아래 그림은 이러한 과정을 시각적으로 잘 보여주고 있다.
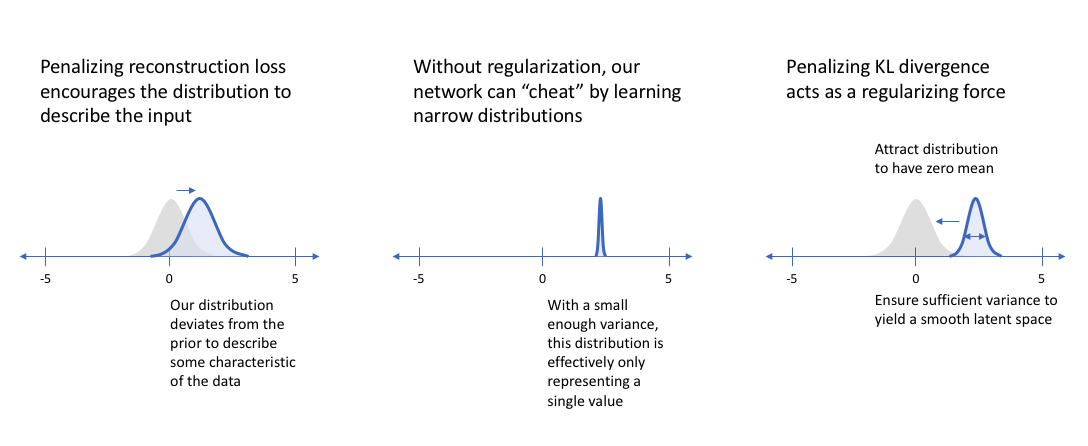
윗 글에서 "z는 다차원 벡터일 수 있고 각 차원이 생성에 있어 임의의 특징을 나타낸다고 볼수 있기 때문에 z를 구성하는 각 차원 값은 정규분포에서 sampling한 값으로 사용하게 된다."를 이야기 하였는데, 이러한 시나리오를 잘 보여주는 그림이 아래의 그림이다.
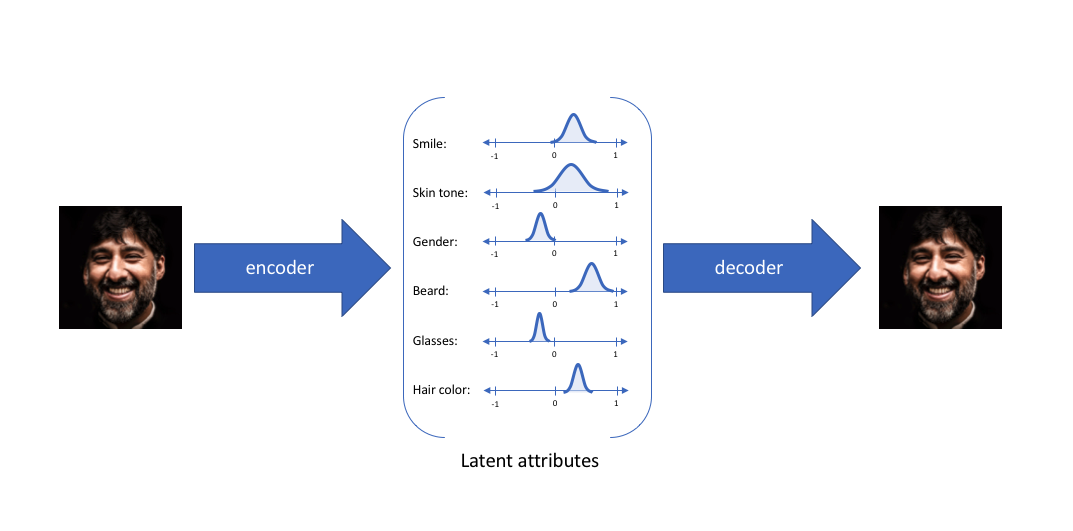
위 그림은 6개의 차원을 갖은 z 이며, z의 6개 특징들은 확률적인 분포로 부터 sampling되고 Decoder로 입력되어 새로운 이미지를 만들게된다.
'Tech-Tip' 카테고리의 다른 글
| 에라토스테네스의 체 (0) | 2023.06.01 |
|---|---|
| 유클리드 호제법 (0) | 2023.05.30 |
| 최신 GPU Spec 체크 (0) | 2023.05.21 |
| 행렬곱 - Xilinx HLS 실험 4 (0) | 2023.02.23 |
| 행렬곱 - Xilinx HLS 실험 3 (0) | 2023.02.23 |